El
código genético
Junto
al ácido nucleico ADN como portador de
la información genética, también participa en ácido ribonucleico ARN, en los procesos
moleculares de la información genética. Aparece en el célula en tres formas:
1.- m-ARN = ARN mensajero o ARN recadero
2.- t-ARN = ARN de transferencia
3.- r-ARN = ARN ribosomal
1.- m-ARN = ARN mensajero o ARN recadero
2.- t-ARN = ARN de transferencia
3.- r-ARN = ARN ribosomal
Todas
estas tres formas de ARN participan de la realización de la información genética,
o sea en la transformación de los genes en el metabolismo. La idea, que la
información genética tiene algo que ver con el metabolismo, lo manifestó por primera
vez Archibald Garrod en 1902. George Beadle y Edward Tatum. Comprobaron esta
relación en 1940 y formularon la hipótesis “Un GEN una ENCIMA” Ellos usaron
rayos X en el hongo neurospora, para provocar mutaciones. Estos afectaron a
genes y encimas individuales en una vía metabólica especial. En 1958 recibieron
el permio Nobel por sus investigaciones.
Hoy
a esta hipótesis se la llama “Un gen, un
poli péptido”, puesto muchas proteínas.
Como por ejemplo, la hemoglobina se compone de varias cadenas de poli péptidos.Esto significa:

Dogma central de la biología molecular
Ya
F. Crick en1953 formuló el flujo de la información del ADN por el ARN hacia los
ribosomas como dogma central de la biología molecular. El ácido ribonucleico (ARN), que está presente tanto en el núcleo
de las células como en el citoplasma, se encarga del rol de trasmisión de la información
genética hacia los proteínas. Se distinguen dos procesos:
●
La transcripción: La copia de genes en una copia genética mARN
● La translación: La síntesis proteica en base a la copia genética mARN
● La translación: La síntesis proteica en base a la copia genética mARN
Idiomas
Idioma alemán: 26
letras abcdefghijklmnopqrstuvwxyz
Combinación de las letras: Arbitrariamente: Ejemplo: Siete 7. Signos de puntuación: ”?/ etc. Secuencia de los signos: Sin sobre posición, espacio.
Código binario: Dos
letras 0, 1. Combinación de los signos. Arbitraria: Ejemplo: 0111 = 7. Puntuación,
ninguna. Secuencia de los signos: Sin sobre posición, sin espacios.
Idioma de las proteínas: 22 letras G - Glycin (Gly) P - Prolin (Pro) A - Alanin (Ala) V - Valin (Val) L - Leucin (Leu) I - Isoleucin (Ile) M - Methionin (Met) C - Cystein (Cys) F - Phenylalanin (Phe) Y - Tyrosin (Tyr) W - Tryptophan (Trp) H - Histidin (His) K - Lysin (Lys) R - Arginin (Arg) Q - Glutamin (Gln) N - Asparagin (Asn) E - Glutaminsäure (Glu) D - Asparaginsäure (Asp) S - Serin (Ser) T - Threonin (Thr) -- Selenocystein (Sec) -- Pyrrolysin (Pyl)  Combinación de los
signos: Arbitraria: Ejemplo: Heptapéptido Gly-Asp-Ala-Phe-Glu-Cys-Ala. Signos de
puntuación: Ninguno. Secuencia de los signos: Sin sobre posición, sin
espacios libres. Combinación de los
signos: Arbitraria: Ejemplo: Heptapéptido Gly-Asp-Ala-Phe-Glu-Cys-Ala. Signos de
puntuación: Ninguno. Secuencia de los signos: Sin sobre posición, sin
espacios libres.Código genético: 4 letras ADN: Adenina (A), Guanina (G), Citocina (C). Tiamina (T). ARN: A; G; C; U = Uracil en vez de tiamina. Combinación de los signos como tripletas, ejemplo: ACG. Signos de puntuación: Codón de inicio y de detención. Secuencia: Sin sobre posición, sin espacios libres; Exones, intrones. |
Los
ribosomas, que se componen 2/3 de ARN,
mejor dicho, rARN, son el lugar de la biosíntesis de las proteínas.
Para
poder producir proteínas, la célula necesita aminoácidos. Los obtienen de los
nutrientes. Moléculas 1-ARN se encargan del transporte en el citoplasma hacia
los ribosomas.
El código genético
Mediante
el auxilio de los ribosomas el “idioma de los genes” es traducido al “idioma de
las proteínas”. Idiomas o grafías poseen como elementos signos, letras y signos especiales.
El idioma alemán se compone de 26 letras. El idioma de los computadores se
componen de dos signos: 0 y 1. Ambos, son almacenados como información en combinaciones de los signos.
El idioma
de las proteínas se compone de 22
letras, los aminoácidos. En la secuencia está contenida la información para la estructura
espacial específica, que les otorga a las proteínas una función concreta.
El idioma genético tiene 4 letras: Adenina,
Guaninas, Citosina, y Tiamina. Qué podría ser más acertado suponer que al igual
en las combinaciones de las bases presumir la información genética. En los años
50 la pregunta sólo era:
¿Cuál era el largo de una palabra genética y que combinación de bases corresponde a un aminoácido?
¿Cuál era el largo de una palabra genética y que combinación de bases corresponde a un aminoácido?
Con una base se podría codificar máximo 4 aminoácidos, demasiado poco. La combinación de dos bases da 4ˆ2 posibilidades, es decir 16 variantes, aun demasiado poco. Con un mínimo de tres bases en combinaciones se tendría la posibilidad. Codificar toso las 22 aminoácidos, máximo 4ˆ3 = 64 posibilidades combinatorias.
 |
| Marschall Nirenberg |
Esto
fue
examinado a los comienzos de los años 60 por Marschall Nirenberg y
Heinrich Matthaei (Premios Nobel de 1968). Ellos adicionaron
en 20 tubos de ensayos, con fragmentos
de células de E.Coli, determinados aminoácidos
una poli U-ARN. En uno de los tubos se firmó un poli péptido, que sólo
se componía de Fenilamina. Y ahí encontraron que una combinación de tres
bases,
una tripleta, contenía la información pata un aminoácido. Puesto que en
los
ribosomas se usa la mARN complementario
para el ADN, el codogene determinante en el ADN para Phe (por sus siglas en alemán) AAA el codón dl mARN UUU.
Mediante
ensayos con las más diversas secuencias de ARN se aclararon todos los codogenes,

Erste Base = Primera base
Zweite Basde = Segunda base
Säure = ácido
Zweite Basde = Segunda base
Säure = ácido
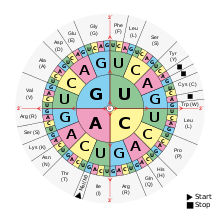 Para
61 aminoácidos se encontraron tripletas codificadoras y 3 terminator o stop
codogenes, para los cuales no existen amino ácidos. Por esta razón se interrumpe
aquí la sínytesi9s de las proteínas, se habla de “Nonsense-codones”. La secuencia
mARN es: UAA, UAG y UGA.
Para
61 aminoácidos se encontraron tripletas codificadoras y 3 terminator o stop
codogenes, para los cuales no existen amino ácidos. Por esta razón se interrumpe
aquí la sínytesi9s de las proteínas, se habla de “Nonsense-codones”. La secuencia
mARN es: UAA, UAG y UGA.
Junto
a la forma tabulada, también es ampliamente conocida el “Sol-Code” según Bresch
u Hausmann. Los codones se leen desde adentro hacia afuera. Fig. Derecha
Ya
que en los ribosomas el código genético es traducido a la forma del mARN, se
especifica el código genético como mARN
en forma de codones. Una representación tabulada se puede ver abajo. Por ejemplo isoleucina
significa AUU, AUC o AUA, puesto, que para un aminoácido pueden corresponder
varios codones, al código genético se le llama degenerado.
Esta
asignación de los aminoácidos se ha encontrado en todos los seres vivientes, por
esto al código genético se la llama universal.
Sólo en las mitocondrias y cloroplastos o las arqueo-bacterias se
encontraran parcialmente otras codificaciones.
Hasta hace unos pocos años sólo se coonocían20 aminoácidos. Entre tanto se encontraron otros 2 aminoácidos, Selenocisteína (Sec) y Pirrolisina (Pyl). Este código no está sobrelapado. Es decir, la secuencia de un gen no es usado por otro gen.
Hasta hace unos pocos años sólo se coonocían20 aminoácidos. Entre tanto se encontraron otros 2 aminoácidos, Selenocisteína (Sec) y Pirrolisina (Pyl). Este código no está sobrelapado. Es decir, la secuencia de un gen no es usado por otro gen.
Un
recorté de un gen podría tener este aspecto:
ADN,
cadena de codones:
|
TAC CTT AAG AGC GAG
|
(3'
<- 5="" span="">
|
ADN,
cadena complementaria
|
ATG GAA
TTC TCG CTC
|
(5'
-> 3')
|
mARN
|
AUG GAA
UUC UCG CUC
|
(5'
-> 3')
|
Proteína
|
Met - Glu - Phe - Ser - Leu
|
COOH
|
¿Ahora,
cuál es el aspecto real de la secuencia de los nucleótidos de un gen? Esto es diferente
para bacterias y paro los eucariotas. Donde las bacterias todo el ADN se
compone de genes, que contienen la información para la confección de proteínas.
En las eucariotas sólo una parte del ADN está destinada para la obtención de
las proteínas. Llamados exones. La
razón de la existencia de la otra parte no se conoce = introne.

Codierende regionen = Regiones codificadoras
Nicht-codirende region = Región no codificadora



Nicht-codirende region = Región no codificadora
Tropomiosyn-gen
Las
zonas celestes son intrones (nonsens), azul oscuro exones (codificadoras).

Un
músculo es un atado de fibras musculosas, que se componen de células
individuales, que son sub unidades funcionales del músculo. Cada fibra posee
muchos núcleos celulares, lo que muestra, que se han desarrollado de muchas
células. Cada fibra contienen muchos orgánulos llamados miofibrillas, que a
su vez se componen de estructuras de orma de varillas compuestas
principalmente por dos proteínas: Actina y miosina.
Adjunto
también participan en la estructuración, la troponina y la tropomiosina
|

En
el ejemplo de la proteína del músculo se ven los exones y los intrones en un
gen de las eucariotas.

La
tropomiosina es una molécula de forma de barra (largo aprox. 400 Å y ancho Å). Se compone de dos a-helicoidales en
paralelo. Muchas moléculas tropomiosinas se apegan cabeza a cabeza y cola
a cola. Un músculo del esqueleto se compone de un 3% de tropomiosina.
 |
| Modelo del transcurso de la transcripción y la traslación |
Ahora
para producir del plano de construcción en el ADN una proteína, primero se
copia, en un proceso complejo, el gen en el núcleo de la célula. Para este
propósito se hace una copia de la secuencia de la base de codogenes de la doble hélice. A esto
proceso se le llama “transcripción”. Esta
copia, llamada m-ARN, viaja desde el núcleo de la célula hacia el citoplasma a
las ribosomas. Allí la secuencia de la base es traducida a la correspondiente
secuencia de las proteínas y se confecciona una proteína. A esto se le denomina
“translación”.
| La trasncrición sde desarrolla en tres pasos 1.- Iniciación 2.- Elongación 3.- Terminación |
1.-
Iniciación
Para
copiar al gen del complejo de la
polimerasa ARN, ata al promotor en un lugar determinado. Para esto se requieren
diferentes factores, como por ejemplo, el factos sigma. La parte siguiente es desconectada
y comienza la formación de una secuencia nucleótido complementaria como mARN (messenger
ARN), a partir del codón de partida.
2.-
Elongación
La
totalidad del complejo de transcripción junto a mARN en formación, se desplaza en
dirección 5’ – 3’ a lo largo del gen, donde el gen, por decir lo así, es copiado en forma complementaria.
3.-
Terminación
Al
alcanzar una secuencia de detención con un codón finalizador se detiene la
copia. El complejo de la polimerasa ARN se separa del ADN.
En
los procariontes este mARN es usado por ribosomas en forma directa como matriz,
para fabricar directamente, desde allí la proteína correspondiente (=
Translación), Donde las eucariotas, la transcripción
primaria (= pre mARN) aún es procesado y
transformado en el mARN n ecesario para la translación. Este proceso de transformación
del pre-mARN en mARN, donde los eucariontes se compone de taponado, poli-adenilación y empalme.
Taponado:
Después de la transcripción el pre-mARN es provisto al final 5’ con un tapón. Aquí,
un nucleótido específico (7-metilguanosina) está ligada en un "enlace del
extremo 5 'de la pre-mRNA 5'-5.
Poli-adenilación:
Al terminal 3’ se agregan 29 y 250 Nucleótidos
de adenina (= Poli-A-cola).

Empalme.
Después son los intrones son extraídos por un complejo (= Espliceosoma) compuesto
por proteínas y ARNs y juntados para formar los exones.
Fuente:
http://www.biokurs.de/skripten/bs11.htm
Traducido
del alemán por A. Gundelach


















{kind=link}
No hay comentarios.:
Publicar un comentario